Binary Classifiers: Precision/Recall Trade-off


Trade-off!! Called so because you can't have it both ways. Either you embrace recall and let go of precision or you make precision the love of your model - no side chick in this game. But accurately stating it will be, the higher the precision, the lower the recall and vice versa.
You can't have your cake and eat it too. (John Heywood, 1546)
Precision - the degree to which a machine learning model accurately predicts or classifies a positive instance.
Recall - the ratio of available positive instances that are predicted or classified by a model.
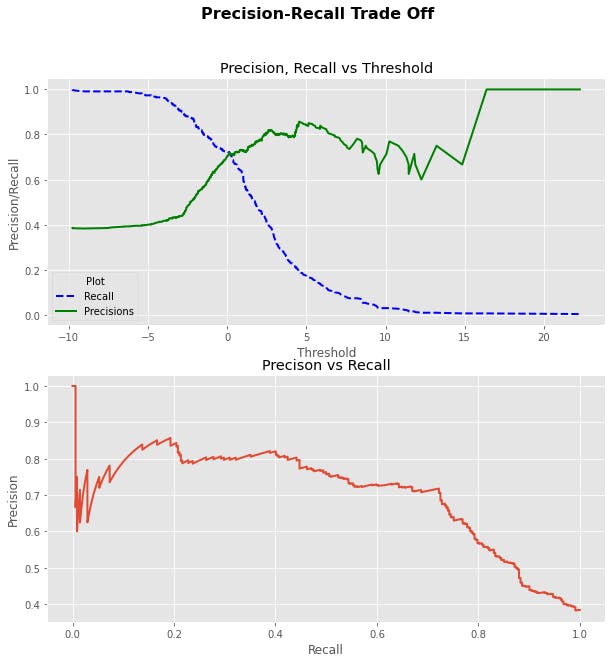
It's all about 0 or 1? A classifier determines if an instance belongs to a class or not. Tall or short, odd or even, adult content or <18, harmless or a security threat, honest customer or a shop lifter. 0 or 1 scenarios are endless. The percentage number of times it does this correctly is the precision while the percentage number of a particular instance it classifies to belonging to a class is the recall. Precision goes for quality while recall is about quantity. To a machine learning model, '6', '3' and '8' can look like '8'. A model built to have high recall will classify all these other numbers as '8' while a precise model will ignore them even though there's a possibility they might actually be '8'.
Code snippet to check the recall and precision score of a model:
from sklearn.metrics import precision_score, recall_score
from sklearn.model_selection import cross_val_predict
y_predicted = cross_val_predict(model, X, y, cv=3)
precision_score = precision_score(y, y_predicted)
recall_score = recall_score(y, y_predicted)
In a proper machine learning project pathway, problem definition and performance metrics comes first. Which boxes must our machine learning construct tick before we share high fives, hugs and declare our machine learning construct a success. For example, if you're tasked to build a model that filters off +18 movies. It's more sensible to build a model having the maximum possible precision level with the possibility of filtering off some quality <18 contents than scarring innocent eyes. But this approach will be a wrong one if the model is meant to predict or classify security threats. A model that cries wolf is better than an accurate one which fails to detect occasional threats. Like the Irish novelist, Samuel Lover's Rory O'More (1837) said, “Better safe than sorry.”
If the code snippet above reveals the precision or recall score of the model falls short of the required performance metric. It can be easily adjusted by manipulating the threshold at which the model is making it's decisions.
y_scores = cross_val_predict(model, X, y, cv=3, method='decision_function')
manipulated_threshold = thresholds[np.argmax(precisions >= 0.95)]
y_manipulated_threshold = (y_scores >= manipulated_threshold)
#0.95(95%) is an example of what the desired performance level may look like.